Window Functions
What is Window Functions
In simple terms window or ranking functions execute on set of rows and return a single aggregated value for each row.
Window functions using an OVER() clause but OVER() optional is some cases (in aggregate types function), it’s have 3 types .
- Aggregate Window Functions like COUNT(),SUM(), MAX(), MIN(), AVG().
- Ranking Window Functions like RANK(), DENSE_RANK(), ROW_NUMBER(), NTILE()
- Value Window Functions like LAG(), LEAD(), FIRST_VALUE(), LAST_VALUE()
1. Aggregate Window Functions
Count (): Just count number records or rows, it’s also accept DISTINCT but can’t able to use when using OVER () clause.
- Count(*): it will count Total number of rows,
- Count(columnname):it will count Total Rows where have values means NULL not count ,
- Count(DISTINCT columnname): count unique column values
SUM (): sum of numeric values, it’s also accept DISTINCT but can’t able to use when using OVER () clause.
- SUM (columnname): it will add/sum Total values of specified
column
- Count(DISTINCT columnname): it will add/sum unique values of specified
AVG (): Just calculating average of numeric column, it’s also accept DISTINCT but can’t able to use when using OVER () clause.
- AVG (columnname): it will calculate average of specified
column for total rows.
- AVG (DISTINCT columnname): it will calculate average of specified column for unique values rows.
MIN (): retrieve a minimum values from specific column its use like MIN (columnname), its generally use in numeric column but it’s also can apply on string column there it will check 1st character and NULL excluding when minimum values retrieve.
MAX (): this same as MIN () but MAX () retrieving maximum values and MIN() is minimum value.
Note: Aggregate function’s always need group by clause when any one column not aggregating but there actual rows/data can’t display means always show Aggregated.
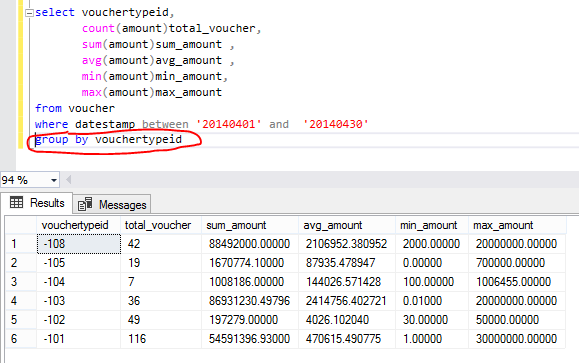
Just see you can’t see your actual data/row if we need to show Aggregated info with actual data then need to use OVER()clause like
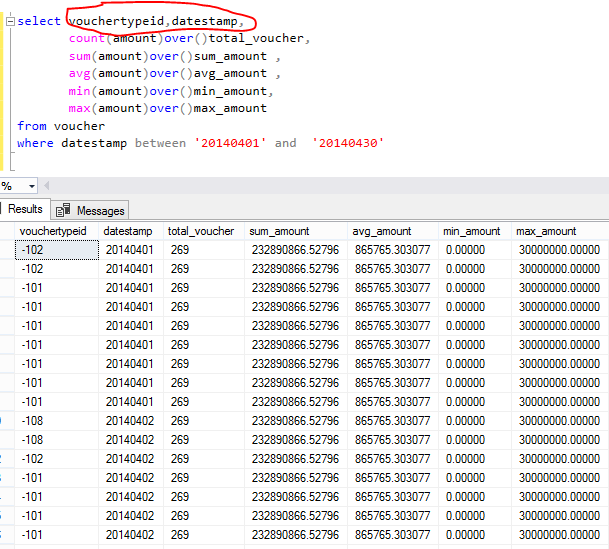
See in query there I’m aggregating data with vouchertypeid, datestamp columns but there group by not using because OVER () used with each aggregate function.
Just Notice there data aggregated on table based if want to any group based then need to use partition option in side of OVER () clause like
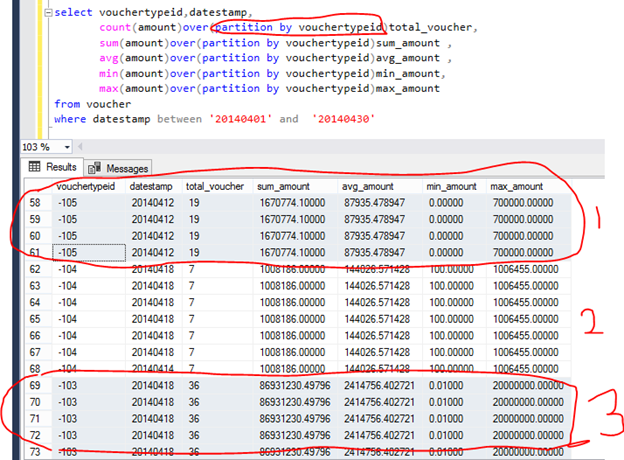
See in query there we have used OVER () clause with PARTITION (based on vouchertypeid column) so aggregating data according to vouchertypeid group.
When need to calculating running aggregation then also need to ORDER BY clause, like
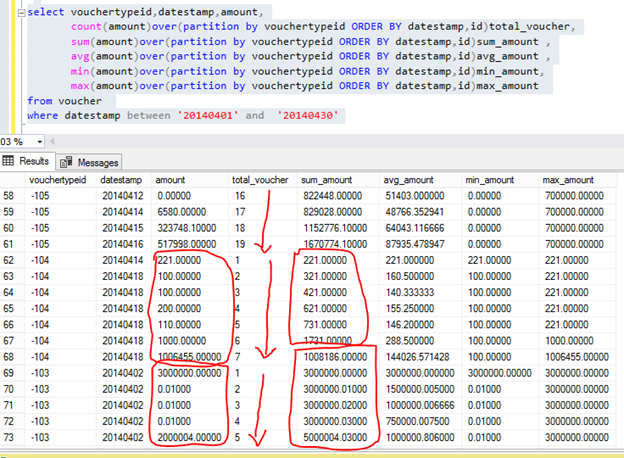
2. Ranking Window Functions
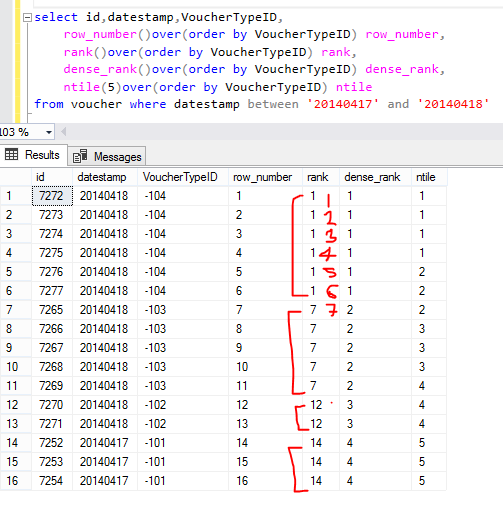
RANKING functions similar aggregate function but ranking function making rank the row values of a specified column according to their rank, RANKING don’t work without OVER (ORDER BY <Columnname>) and PARTITION BY clause is optional for all RANKING functions.
ROW_NUMBER (): Used for give a unique row number to each record based on the specified column value, clause.
RANK (): Its also use to give rank for each row but it have two records with same value then the RANK() function will assign the same rank to both records and it will skipping the next rank.
DENSE_RANK ():The DENSE_RANK() same as RANK() but it does not skip any rank, means if 2 same value come then it will assign same rank but it will not skip in next rank .
NTILE (): NTILE divides rows into equal sized buckets. Like we have 10 rows and NTILE (5) then it will divide 10 into 5 buckets with 2 rows each. When use NTILE (6), then it will divided 6 buckets with 2 rows in starting 4 buckets and 1-1 row in last 2 bucket.
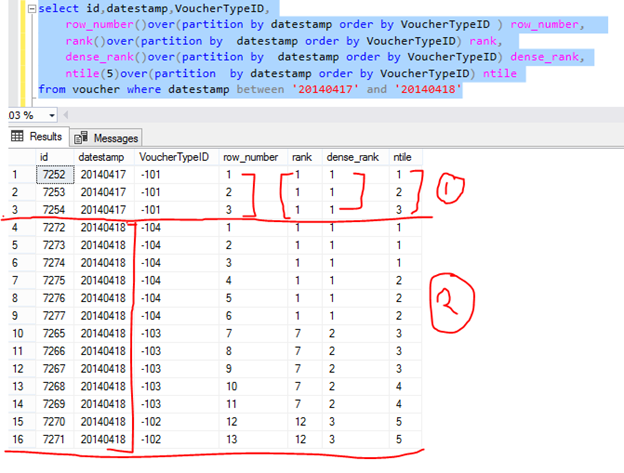
When using PARTITION BY clause then it makes groups ,in below example I have created partition on datestamp column and VoucherTypeID column means it will making group on datestamp column and give ranking on VoucherTypeID like
3. Value Window Functions
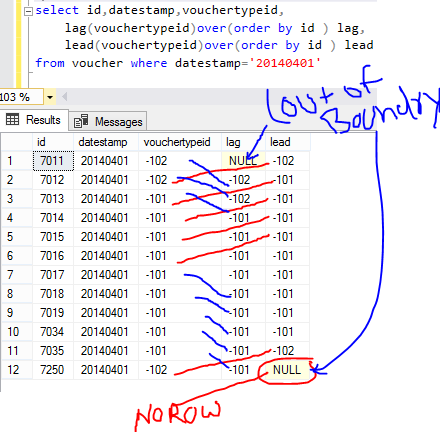
Lag function also similar to ranking functions but Lag helps to access values from previous records, and Lead function helps to access values from next records in the data set.
LAG (): Lag function retrieving values from previous without using self-join.
LEAD (): Lead function retrieving values from next without using self-join.
Syntax:
LAG / LEAD ([column name],[offset],[default value]) OVER([[PARTITION BY] column name]| ORDER BY column name)
Offset: Optional parameter, its default values is 1. It is decide how many rows travel from the current row in a result set.
Default: Optional parameter, its default values is null, if the offset goes out of the bounds from the result set then it will return default value PARTITION BY: This one also Optional parameter in OVER () clause and it is work same as Ranking and aggregate.
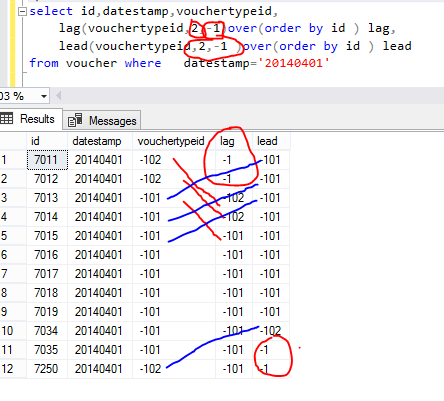
-1 showing where was null value in above screen short and 2 row values jumping because there offset 2 set and default value is -1 assign.
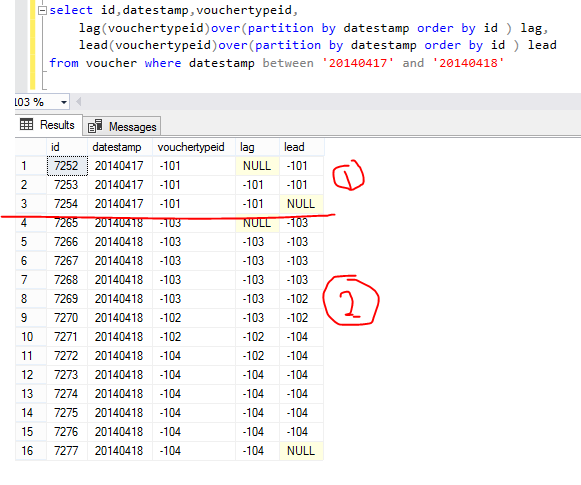
There we have use PARTITION clause so there 2 groups created according to datestamp column
FIRST_VALUE (): returns the first value from result set.
FIRST_VALUE () ,LAST_VALUE (): returns the Last value from result set.
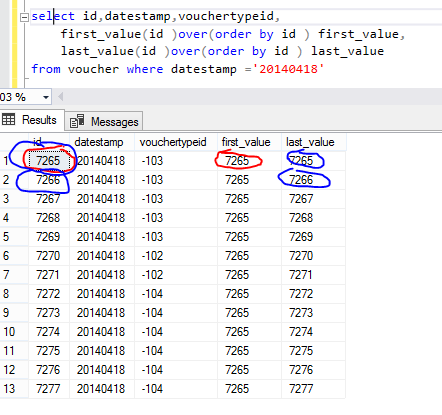
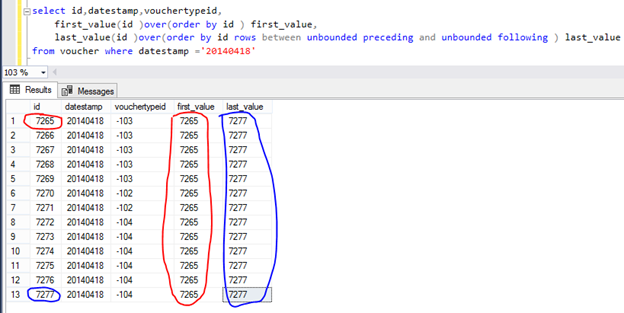
See above screen short there first_value picked as minimum values from result set but last_values picked as id values because its checking max id as current rows value but we want to pick last id from this result set then need to s upper and lower bound like
select id,datestamp,vouchertypeid,
first_value(id )over(order by id ) first_value,
last_value(id )over(order by id rows between unbounded preceding and unbounded following ) last_value
from voucher where datestamp =’20140418′
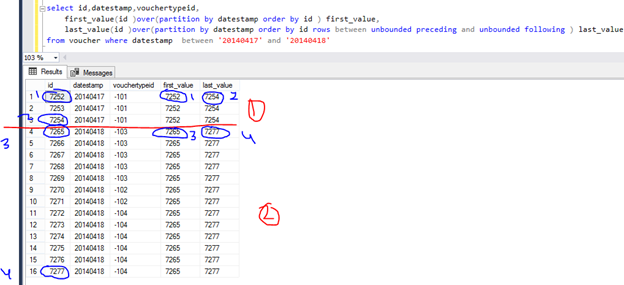
When need to get first and last value according to group then we can use partition like
PERCENTILE_CONT():use for calculating a median but takes average of the two values closest to the middle.
PERCENTILE_DISC(): use for calculating a median but will return a value that exists in the set. Ex.1
Ex.1
select vehicle_id ,
percentile_cont(0.5) within group(order by vehicle_id) over() as percentilecont,
percentile_disc(0.5) within group(order by vehicle_id) over() as percentiledisc
from vehicles where company_id=1 and vehicle_id<22
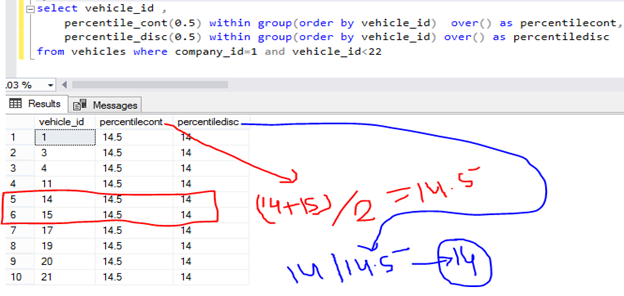
Formula 1: total_rows%2=1 then it will x= (total_rows/2)+1 row value print
Formula 2: total_rows%2=0 then row_value1=(total_rows/2), row_value2=(total_rows/2)+1, x=(row_value1+row_value2)/2) value print
For Ex1 have 10 rows so 10/2=0 so Formula 2 will apply rowval1=(10/2)=>5 and values of row 5 is 14 so rowval1=14 and rowval2=(10/2)=>5+1 means rownumber 6th values is 15 so (14+15)/2=14.5 so x=14.5 Is Percentile_Cont
=> Percentile_Cont value not exists in result set but 14 exists so 14 as Percentile Disc
Ex.2

There formula1 will apply for percentilecount because total rows are 11 so 11%2=1 so 11/2=5+1 will select


Recent Comments